동시성에서의 논 블로킹 알고리즘이란 쓰레드간의 공유된 상태(자원)로의 접근을 서로의 중단 없이 수행하도록 하는 것이다. 보다 일반적인 용어로 말하자면, 어떤 알고리즘에서 한 쓰레드의 정지가 여기에 관련된 다른 쓰레드의 정지를 유발하지 않는다면 이 알고리즘을 논 블로킹 알고리즘이라 한다.
블로킹과 논 블로킹 동시성 알고리즘의 차이를 보다 잘 이해하기 위해서 먼저 블로킹 알고리즘을 다루고 이어서 논 블로킹 알고리즘을 다루도록 한다.
블로킹 동시성 알고리즘
다음과 같은 알고리즘을 블로킹 동시성 알고리즘이라 한다.
- A: 쓰레드에 의해 요청된 동작을 수행 - 또는
- B: 쓰레드가 동작을 수행할 수 있을 때까지 대기
많은 종류의 블로킹 알고리즘과 동시성 블로킹 자료구조가 있다. 예를 들어, java.util.concurrent.BlockingQueue 인터페이스의 구현체들은 모두 블로킹 자료구조이다. 쓰레드가 BlockingQueue 에 엘레멘트를 삽입하려 하는데 큐에 공간이 없다면 쓰레드는 공간이 생길 때까지 대기한다.
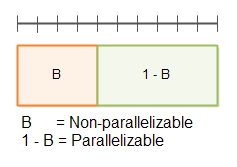
다음 다이어그램은 공유된 자료구조를 보호하는 블로킹 알고리즘의 동작을 보여준다.

논 블로킹 동시성 알고리즘
다음과 같은 알고리즘을 논 블로킹 동시성 알고리즘이라 한다.
- A: 쓰레드에 의해 요청된 동작을 수행 - 또는
- B: 요청된 동작이 수행될 수 없는 경우 이를 요청 쓰레드에게 통지
자바는 몇몇 논 블로킹 자료구조를 가지고 있다. AtomicBoolean, AtomicInteger, AtomicLong, AtomicReference 클래스들은 모두 논 블로킹 자료구조의 예이다.
다음 다이어그램은 공유된 자료구조를 보호하는 논 블로킹 알고리즘의 동작을 보여준다.

논 블로킹 vs 블로킹
블로킹과 논 블로킹 알고리즘의 주된 차이점은 위 각 알고리즘의 동작 설명 중 두 번째 단계에 있다. 다시 말해서, 블로킹 알고리즘과 논 블로킹 알고리즘의 차이는 요청된 동작이 수행될 수 없을 때 어떻게 대응하느냐에 있다.
블로킹 알고리즘은 쓰레드가 요청한 동작이 수행 가능해질 때까지 대기한다. 논 블로킹 알고리즘은 요청된 동작이 현재 수행 불가능하다는 사실을 쓰레드에게 알린다.
블로킹 알고리즘을 사용하면 쓰레드는 요청 동작이 수행 가능해질 때까지 대기하게 될 수 있다고 했는데, 이것은 일반적으로 첫번째 스레드가 요청된 작업을 수행할 수 있게 하는 다른 쓰레드의 동작이 된다. 어떤 이유로 쓰레드가 어플리케이션의 다른 곳에서 동작이 중단되어 첫번째 스레드가 요청한 작업을 수행할 수 없는 경우 첫번째 쓰레드는 무기한, 혹은 다른 쓰레드가 필요한 동작을 수행할 때까지 중단된다.
예를 들어, 쓰레드가 꽉 찬 BlockingQueue 안에 엘레멘트를 삽입하려 하면 이 쓰레드는 다른 쓰레드가 큐에서 엘레멘트를 꺼내갈 때까지 동작이 중단된다. 만일 어떤 이유로 큐에서 엘레멘트를 꺼내가야 할 쓰레드의 동작이 어플리케이션의 다른 영역에서 중단된다면, 큐에 엘레멘트를 삽입하기 위해 대기중인 쓰레드의 중단 상태는 해제되지 못한다. 대기 상태는 무기한 지속되거나, 혹은 다른 쓰레드가 큐에서 엘레멘트를 꺼내갈 때까지 지속된다.
논 블로킹 동시성 자료구조
멀티쓰레드 시스템에서 쓰레드들은 일반적으로 어떤 종류의 자료구조를 통해 서로 협업한다. 단순한 형태의 다양한 자료구조에서부터 큐, 맵, 스택과 같은 보다 발전된 형태의 자료구조들 중 어느 것이든 이러한 자료구조로 사용될 수 있다. 다수의 쓰레드의 동시 접근에 제대로 기능하기 위해, 자료구조는 반드시 동시성 알고리즘에 의해 보호되어야 한다. 이런 알고리즘이 자료구조를 동시성 자료구조로 만드는 것이다.
동시성 자료구조를 보호하는 알고리즘이 쓰레드를 중단시키는 방법을 통한다면 이 알고리즘을 블로킹 알고리즘이라 한다. 고로, 자료구조는 블로킹 동시성 자료구조가 된다.
동시성 자료구조를 보호하는 알고리즘이 쓰레드를 중단시키지 않는 방법을 통한다면 이 알고리즘을 논 블로킹 알고리즘이라 한다. 고로, 자료구조는 논 블로킹 동시성 자료구조가 된다.
이런 각 동시성 자료구조는 특정한 방법의 쓰레드 간 협업을 지원하기 위해 설계되었다. 어떤 동시성 자료구조를 사용할 것이냐는 쓰레드 간 협업이 어떤 방식으로 이루어진 것이냐에 달려있다. 다음 섹션에서 몇가지 논 블로킹 자료구조를 다루면서 어떤 상황에 이 자료구조들이 사용될 수 있는지 설명한다. 논 블로킹 자료구조의 동작 방식에 대한 설명은 논 블로킹 자료구조의 설계와 구현에 대한 방안을 제공할 것이다.
volatile 변수
자바 volatile 변수는 변수의 값을 항상 메인 메모리에서 직접 읽히도록 한다. volatile 변수에 새 값이 대입되면 이 값은 언제나 메인 메모리로 즉시 쓰여진다. 이 동작은 다른 CPU 에서 동작하는 다른 쓰레드에게 항상 volatile 변수의 최신 값이 읽히도록 보장한다. volatile 변수의 값은 CPU 캐시가 아닌 메인 메모리로부터 직접 읽히게 된다.
volatile 변수는 논 블로킹이다. volatile 변수로의 쓰기는 원자적 연산이고, 다른 쓰레드가 끼어들 수 없다. 하지만 volatile 변수라 할지라도 연속적인 읽기-값 변경-쓰기 동작은 원자적이지 않다. 다음 코드는 둘 이상의 쓰레드에 의해 수행된다면 여전히 경합을 유발한다.
volatile myVar = 0;
...
int temp = myVar;
temp++;
myVar = temp;
처음에 volatile 변수인 myVar 의 값은 메인 메모리로부터 읽어들여 temp 변수로 대입된다. 다음으로 temp 변수의 값은 1 증가된다. 그리고 temp 변수의 값은 myVar 로 다시 대입되어, 값은 메인 메모리로 저장된다.
두 쓰레드가 이 코드를 실행하여 똑같이 myVar 을 읽고, 값을 1 증가시키고, 값을 메인 메모리로 저장한다면, myVar 의 증가되는 값은 2 가 아닌, 1 이 될 여지가 있다. (예: 두 쓰레드가 값 19 를 읽어 각각 값을 증가시키고 저장하지만 결과값은 21 이 아닌 20 이 된다.)
위와 같은 코드를 작성할 일은 아마도 없겠지만, 위 코드는 사실 아래 코드와 동일하다.
myVar++;
위 코드가 실행되면 myVar 의 값은 CPU 레지스터 또는 CPU 캐시로 읽히고, 1 증가되고, CPU 레지스터나 CPU 캐시에서 다시 메인 메모리로 저장된다.
The Single Writer Case
공유 변수로 쓰기를 수행하는 쓰레드가 하나이고 이 변수를 읽는 쓰레드가 다수일 때는 어떠한 경합도 발생하지 않는다. 읽기 쓰레드가 몇 개이든 아무런 문제가 되지 않는다. 따라서 쓰기 쓰레드가 하나인 경우라면 언제든 volatile 변수를 사용해도 좋다.
경합 조건은 다수의 쓰레드가 같은 공유 변수에 대해 읽기-값 변경-쓰기 순서의 연산을 수행할 때 발생한다. 읽기-값 변경-쓰기 연산을 수행하는 쓰레드가 하나 뿐이고, 나머지 모든 쓰레드는 읽기 연산만을 수행한다면 경합 조건은 발생하지 않는다.
다음은 synchronized 를 사용하지 않고도 동시성을 유지하는 single writer counter 이다.
public class SingleWriterCounter {
private volatile long count = 0;
/**
* 오직 한 쓰레드만 이 메소드를 호출해야 함.
* 그렇지 않으면 경합 조건을 유발할 수 있음.
*/
public void inc() {
this.count++;
}
/**
* 다수의 읽기 쓰레드가 이 메소드를 호출할 수 있음.
* @return
*/
public long count() {
return this.count;
}
}
inc() 메소드를 호출하는 쓰레드가 하나라는 전제에 한하여 SingleWriterCounter 클래스의 인스턴스는 다수의 쓰레드가 접근할 수 있다. 이 말은 inc() 메소드를 호출하는 쓰레드가 한 시점에 하나여야 한다는 뜻이 아니다. 시점을 막론하고 오직 한 쓰레드만이 inc() 를 호출하여야 한다. count() 메소드는 다수의 쓰레드에 의해 호출될 수 있으며, 이는 어떠한 경합 조건도 유발하지 않는다.
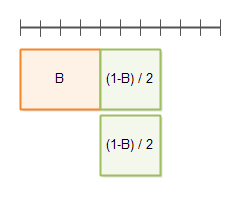
다음 다이어그램은 다수의 쓰레드가 volatile 변수 count 로 어떻게 접근하는지 보여준다.

volatile 기반의 더 발전된 자료구조
volatile 변수로의 쓰기 쓰레드가 하나이고 읽기 쓰레드가 둘 이상인 경우에 volatile 변수의 조합을 사용하는 자료구조를 만들 수 있다. 각 volatile 변수는 각각의, 서로 다른 쓰기 쓰레드가 접근할 수 있다(volatile 변수 하나당 하나의 쓰기 쓰레드이다. 즉 한 volatile 변수로의 쓰기 쓰레드는 역시 반드시 하나여야 한다.) 이런 구조를 가진 자료구조를 사용하면 쓰레드들이 논 블로킹 방식으로 서로 정보를 주고받을 수 있다.
다음은 두 개의 쓰기 카운터를 가진 간단한 클래스이다. 어떻게 구현되었나 보자.
public class DoubleWriterCounter {
private volatile long countA = 0;
private volatile long countB = 0;
/**
* 오직 한 쓰레드만이 이 메소드를 호출해야 함.
* 그렇지 않으면 경합 조건을 유발할 수 있음.
*/
public void incA() { this.countA++; }
/**
* 오직 한 쓰레드만이 이 메소드를 호출해야 함.
* 그렇지 않으면 경합 조건을 유발할 수 있음.
*/
public void incB() { this.countB++; }
/**
* 다수의 읽기 쓰레드가 이 메소드를 호출할 수 있음.
*/
public long countA() { return this.countA; }
/**
* 다수의 읽기 쓰레드가 이 메소드를 호출할 수 있음.
*/
public long countB() { return this.countB; }
}
DoubleWriterCounter 클래스는 이제 두 volatile 변수를 가진다. 그리고 각각의 증가, 읽기 메소드를 따로 가진다. incA() 메소드를 호출하는 쓰레드는 하나여야 하고, 마찬가지로 incB() 를 호출하는 쓰레드도 하나여야 한다. incA() 호출 쓰레드와 incB() 호출 쓰레드는 달라도 된다. countA() 와 countB() 메소드 호출은 어떤 쓰레드든 상관없이 가능하다. 여기에 경합 조건은 없다.
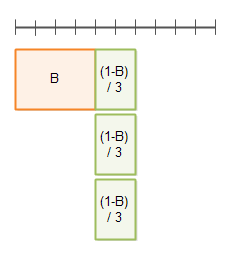
DoubleWriterCounter 클래스는 두 쓰레드간의 협업에 사용될 수 있다. 두 카운트 변수는 생산-소비 형태로 사용된다. 다음 다이어그램은 위와 같은 자료구조를 이용한 두 쓰레드간의 협업을 나타낸다.

눈치 빠른 독자들은 두 개의 SingleWriterCounter 인스턴스를 사용함으로 DoubleWriteCounter 를 사용하는 것과 같은 효과를 얻을 수 있다는 사실을 알 것이다. 필요에 따라 SingleWriterCounter 인스턴스의 수를 얼마든지 늘려서 사용할 수 있다.
컴페어 스왑을 통한 낙관적 락
다중 쓰기 쓰레드들의 공유 변수로의 접근이 꼭 필요한 상황이라면 volatile 변수만으로는 충분하지 못하다. 타 쓰레드의 접근을 배제할 수 있는 방법이 필요하다. 일단 synchronized 블록을 통한 상호 배제를 보자.
public class SynchronizedCounter {
long count = 0;
public void inc() {
synchronized(this) {
count++;
}
}
public long count() {
synchronized(this) {
return this.count;
}
}
}
inc() 와 count() 메소드는 synchronized 블록을 사용한다. 우리는 이러한 방식(synchronized 블록과 wait()-notify() 호출 등등)의 동기화를 피하고자 한다.
synchronized 블록을 사용하는 대신 우리는 자바의 원자적 변수를 사용한다. 여기서는 AtomicLong 이 그것이다. AtomicLong 을 사용하면 위 클래스가 어떻게 변하는지 보자.
import java.util.concurrent.atomic.AtomicLong;
public class AtomicCounter {
private AtomicLong count = new AtomicLong(0);
public void inc() {
boolean updated = false;
while(!updated){
long prevCount = this.count.get();
updated = this.count.compareAndSet(prevCount, prevCount + 1);
}
}
public long count() {
return this.count.get();
}
}
AtomicCounter 는 SynchronizedCounter 와 마찬가지로 쓰레드 세이프하다. 여기서 흥미로운 점은 inc() 메소드의 구현이다. inc() 메소드는 더이상 synchronized 블록을 사용하지 않는다. 대신 다음과 같은 코드가 있다.
boolean updated = false;
while(!updated){
long prevCount = this.count.get();
updated = this.count.compareAndSet(prevCount, prevCount + 1);
}
위 코드는 원자적 연산은 아니다. 즉 두 개의 서로 다른 쓰레드가 동시에 inc() 메소드를 호출하여 long prevCount = this.count.get(); 코드를 실행하는 일이 가능하다. 두 쓰레드 모두 count 가 증가하기 전의 값을 얻을 수 있다. 여기까진 어떠한 경합도 발생하지 않는다.
여기서 중요한 코드는 while 루프 안의 두 번째 라인에 있다. compareAndSet() 메소드 호출은 원자적 연산이다. 이 메소드는 AtomicLong 내부의 기존 값과 내부의 값이라 예상되는 값을 비교하여 두 값이 일치한다면 새로운 값을 세팅한다. 이 동작의 수행은 일반적으로 CPU 의 컴페어 스왑 명령을 직접 사용한다. 때문에 synchronized 블록은 필요치 않으며, 쓰레드를 중단할 일도 없다. 덕분에 쓰레드 중단에 따르는 오버헤드는 발생하지 않는다.
AtomicLong 의 내부 값이 20 이라고 하면, 두 쓰레드는 이 값을 읽는다. 그리고 compareAndSet(20, 20 + 1) 을 호출한다. compareAndSet() 메소드는 원자적 연산이므로, 실행은 순차적으로 이루어진다(한 시점에 한 번).
첫 번째 쓰레드는 예상 값 20(counter 의 이전 값)을 AtomicLong 의 내부 값과 비교한다. 두 값은 일치하고, AtomicLong 은 내부 값을 21 로 세팅한다(20 + 1). updated 변수는 true 가 되고 while 루프는 정지된다.
이제 두 번째 쓰레드를 보자. 쓰레드는 compareAndSet(20, 20 + 1) 을 호출한다. AtomicLong 의 내부 값은 더이상 20 이 아니다. 이 호출은 실패한다. AtomicLong 의 내부 값은 21 로 세팅되지 않는다. updated 변수는 false 가 되고, while 루프는 계속된다. 이번엔 내부 값 21 을 읽어서 1 증가된 값인 22 를 세팅하려 시도한다. 이 과정에서 다른 쓰레드의 개입이 없다면 이 시도는 성공하고 AtomicLong 의 값은 22 가 된다.
왜 낙관적 락인가?
이전 섹션의 코드는 낙관적 락이라 불린다. 낙관적 락은 종종 비관적 락이라 불리는, 전통적인 락과는 차이가 있다. 전통적인 락은 synchronized 블록이나 기타 락을 사용해 공유 메모리로의 접근을 차단한다. 이런 방식은 쓰레드의 중단을 일으킨다.
낙관적 락은 쓰레드의 접근을 차단하지 않고, 모든 쓰레드가 공유 메모리의 복제본을 생성한다. 쓰레드는 자신이 가진 본사본의 데이터를 수정할 수 있으며, 수정된 데이터를 공유 메모리로 쓰기 시도할 수 있다. 다른 쓰레드가 이 데이터를 변경하지 않았다면 컴페어 스왑 연산을 통해 쓰기 쓰레드는 공유 메모리의 데이터를 변경할 수 있다. 만약 다른 쓰레드가 먼저 데이터를 변경했다면, 쓰기 쓰레드는 변경된 새로운 값을 읽어서 다시 변경을 시도한다.
이것이 낙관적 락이라 불리는 이유는, 쓰레드가 데이터의 복제본을 얻어서 데이터를 변경하고 이 변경을 적용하는 동작이, 이 과정에서 다른 쓰레드가 데이터를 변경하지 않았다는 낙관적인 추정 하에 이루어지기 때문이다. 이 추정이 맞는다면 쓰레드는 락 없이 공유 메모리의 데이터를 변경하는 작업에 성공한다. 추정이 틀린다면 쓰레드의 변경 작업은 실패하지만, 여전히 락은 없다.
낙관적 락은 공유 메모리의 경합이 낮거나 중간 수준일 때 가장 잘 동작하는 경향이 있다. 경합이 매우 높으면, 쓰레드는 많은 CPU 싸이클을 공유 메모리를 복제하고 변경하는 데에 낭비하게 되고 공유 메모리로 데이터의 변경을 쓰는 데에 실패하게 된다. 이런 경우에는 경합을 낮추는 방향으로 코드를 재설계할 것을 권한다.
낙관적 락은 논 블로킹
여기서 소개한 낙관적 락 메카니즘은 논 블로킹이다. 한 쓰레드가 공유 메모리의 복제본을 얻어 데이터를 변경하는 과정에서 어떤 이유로 정지상태가 되더라도 같은 공유 메모리로 접근하는 다른 쓰레드들이 정지되는 일은 없다.
전통적인 락/언락 패러다임에서는 한 쓰레드가 락을 걸면 이 락은 락을 건 쓰레드에 의해 해제될 때까지 다른 쓰레드들의 접근을 차단한다(정지상태). 락을 건 쓰레드가 어떤 이유로 정지상태가 되면, 락은 매우 오랜 시간동안 해제되지 않은 상태로 유지된다. -무기한 지속될 수 있다.
교체될 수 없는 자료구조(Non-swappable Data Structures)
컴페어 스왑을 통한 낙관적 락은 공유 자료구조에 알맞게 동작한다. 이 공유 자료구조는 단일 컴페어 스왑 연산에서 전체 자료구조가 새로운 자료구조로 교체될 수 있는(swappable) 성질을 가진다. 그러나 전체 자료구조를 변경된 복제본으로 교체하는 일이 언제나 가능한 것은 아니다.
공유 자료구조가 큐라고 해보자. 이 큐에 엘레멘트를 넣거나 빼려고 하는 각 쓰레드는 먼저 큐의 전체 복제복을 가지고 이 복제본의 데이터를 변경한다. 이 동작은 AtomicReference 를 통해 이루어진다. 참조를 복제하고, 큐를 복제하여 수정하고, AtomicReference 안의 참조를 새로 생성된 큐와 교체한다.
하지만 자료구조의 크기가 클 경우 이러한 복제 동작은 많은 메모리와 CPU 싸이클을 요구한다. 어플리케이션의 메모리 사용량을 증가시키고, 많은 시간이 낭비된다. 이는 결국 어플리케이션의 성능에 영향을 미치는데, 특히 자료구조에 대한 경합이 높을 경우 이 영향은 더욱 심해진다. 뿐만 아니라, 쓰레드가 자료구조를 복제하고 수정하는 시간이 길수록 다른 쓰레드가 중간에 자료구조를 수정했을 가능성이 높아진다. 알다시피 다른 쓰레드가 공유 자료구조를 복제하여 수정하면 자료구조가 복제된 이후로 다른 쓰레드들은 복제-수정 작업을 다시 시작해야 한다. 그리고 이것은 성능과 메모리 소비량에 더욱 큰 영향을 미친다.
다음 섹션에서는 복제-수정이 아닌, 동시에 수정할 수 있는 논 블로킹 자료구조의 구현 방안에 대하여 소개한다.
변경 예정 공유하기
쓰레드는 전체 자료구조를 복제하고 수정하는 대신, 공유 자료구조의 변경 예정을 공유할 수 있다. 공유 자료구조를 변경하려는 쓰레드의 프로세스는 다음과 같다.
- 다른 쓰레드가 변경 예정을 공유 자료구조로 전달했는지 확인한다.
- 공유 자료구조로 변경 예정을 전달한 쓰레드가 없다면, 변경 예정을 만든다. 그리고 이 예정을 공유 자료구조로 전달한다(컴페어 스왑)
- 공유 자료구조의 변경을 수행한다.
- 다른 쓰레드에게 예정된 변경이 수행되었음을 알리기 위해 변경 예정으로의 참조를 제거한다.
보다시피 두 번째 스탭에서 다른 쓰레드의 변경 예정 전달은 차단된다. 이로 인해 두 번째 스탭은 공유 자료구조에 락을 건 것과 같이 동작한다. 한 쓰레드가 변경 예정을 성공적으로 전달했다면, 공유 자료구조에 변경이 수행될 때까지 다른 쓰레드는 변경 예정을 전달할 수 없다.
쓰레드가 변경 예정을 전달한 뒤 다른 작업을 수행하던 중 동작이 정지된다면, 공유 자료구조는 락이 걸린다. 공유 자료구조는 자료구조를 사용하는 쓰레드를 직접 정지시키지 않는다. 공유 자료구조에 변경 예정을 전달할 수 없음을 인지한 쓰레드는 다른 작업을 수행한다. 물론 이 동작은 필요에 따라 바꿀 수 있다.
완료될 수 있는 변경 예정
공유 자료구조로 전달된 변경 예정은 자료구조에 락을 걸 수 있다. 변경 예정 객체는 다른 쓰레드가 변경을 완료했음을 알 수 있는 충분한 정보를 가지고 있어야 한다. 따라서 변경 예정을 전달한 쓰레드가 변경을 완료하지 못하면 다른 쓰레드가 이를 대신하여 그 변경을 완료하고 다른 쓰레드가 공유 자료구조를 사용할 수 있도록 유지할 수 있다.
다음 다이어그램은 여기서 설명한 논 블로킹 알고리즘의 설계를 보여준다.

변경은 반드시 하나 이상의 컴페어 스왑 연산으로 수행되어야 한다. 두 쓰레드가 예정된 변경을 완료하려 시도하면 그 중 한 쓰레드만이 컴페어 스왑 연산을 완료할 수 있다. 그리고 컴페어 스왑 연산이 완료된 직후의 다음 시도는 실패한다.
A-B-A 문제
위 다이어그램의 알고리즘은 A-B-A 문제에 부딪힐 수 있다. A-B-A 문제란 어떤 변수의 값이 A 에서 B 로 변경되었는데 다시 A 로 돌아가는 상황을 가리킨다. 다른 쓰레드는 변수가 실제로 변경되었는지 감지할 수 없다.
쓰레드 A 가 진행중인 변경을 확인하고 데이터를 복제한 뒤 쓰레드 스케쥴러에 의해 동작이 중단되면, 그 사이 쓰레드 B 는 공유 자료구조에 접근할 수 있다. 쓰레드 B 가 공유 자료구조를 완전히 변경한 뒤 변경 예정을 삭제하면, 쓰레드 A 에게는 자신이 데이터를 복제한 이후로 공유 자료구조에 어떠한 변경도 발생하지 않았던 것처럼 보이게 된다. 그러나 변경은 발생하였고, 쓰레드 A 는 자신이 복제했었던 데이터(쓰레드 B 가 데이터를 변경하기 전)를 기준으로 자신의 변경을 수행한다.
다음 다이어그램이 위와 같은 A-B-A 문제를 보여준다.

A-B-A 문제의 해결책
A-B-A 문제의 해결책으로 널리 알려진 방법은 데이터 변경 시에 변경 예정 객체의 포인터만 교체하는 것이 아니라, 포인터와 카운터를 함께 교체하는 것이다. 이 교체는 단일 컴페어 스왑 연산을 사용한다. 이 방법은 C 와 C++ 과 같은 포인터를 지원하는 언어에서 구현 가능하다. 현재 변경 객체의 포인터가 '진행중인 변경 없음' 을 나타낸다 해도, 포인터+카운터에서 카운터가 증가되어 변경 사실을 인지시켜준다.
자바에서 참조와 카운터를 한 변수로 묶는 일은 불가능하다. 대신 자바는 AtomicStampedReference 클래스를 제공한다. 이 클래스는 컴페어 스왑 연산을 사용해서 참조와 스탬프를 교체할 수 있다.
논 블로킹 알고리즘 템플릿
아래 코드는 논 블로킹 알고리즘의 구현 방법을 보여주는 코드 템플릿이다. 이 템플릿은 본문에서 설명된 내용을 근거로 한다.
NOTE: 나는 논 블로킹 알고리즘에 있어 전문가가 아니기 때문에, 이 템플릿에는 몇 가지 오류가 있을 수 있다. 이 템플릿을 당신의 논 블로킹 알고리즘 구현물의 기반으로 삼지 않도록 하라. 이 템플릿은 논 블로킹 알고리즘이 어떤 식으로 구현될 수 있는지에 대한 방향을 제공할 뿐이다. 논 블로킹 알고리즘을 스스로 구현하고 싶다면 실제 논 블로킹 알고리즘 구현체를 두고 연구해야 한다.
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.concurrent.atomic.AtomicStampedReference;
public class NonblockingTemplate {
public static class IntendedModification {
public AtomicBoolean completed =
new AtomicBoolean(false);
}
private AtomicStampedReference<IntendedModification>
ongoingMod =
new AtomicStampedReference<IntendedModification>(null, 0);
// 자료구조의 상태를 선언한다.
public void modify() {
while(!attemptModifyASR());
}
public boolean attemptModifyASR(){
boolean modified = false;
IntendedModification currentlyOngoingMod =
ongoingMod.getReference();
int stamp = ongoingMod.getStamp();
if(currentlyOngoingMod == null){
//변경 예정을 만들기 위한 자료구조 상태를 복제한다.
//변경 예정을 준비한다.
IntendedModification newMod =
new IntendedModification();
boolean modSubmitted =
ongoingMod.compareAndSet(null, newMod, stamp, stamp + 1);
if(modSubmitted){
//컴페어 스왑 연산을 통해 변경을 완료한다.
//note: 다른 쓰레드가 컴페어 스왑 연산의 완료를 도울 수 있기 때문에,
//CAS 는 실패할 수 있음.
modified = true;
}
} else {
//진행중인 변경 작업을 완료하려고 시도하므로, 이 쓰레의 접근을 허용하기 위해
//자료구조는 해제된다.
modified = false;
}
return modified;
}
}
논 블로킹 알고리즘 구현의 어려움
논 블로킹 알고리즘을 제대로 설계하고 구현하기란 난이도가 상당한 일이다. 논 블로킹 알고리즘을 구현하려 한다면, 직접 해보기에 앞서 다른 사람이 구현한 기존의 논 블로킹 알고리즘을 참고하기 바란다.
자바에는 이미 몇가지 논 블로킹 구현체가 있고(ex: ConcurrentLinkedQueue), 앞으로 선보일 자바에서 더 추가될 예정이다.
자바의 내장 논 블로킹 자료구조에 더하여 당신이 사용할 수 있는 몇가지 오픈소스 논 블로킹 자료구조가 있다. 예로, LMAX Disrupter(큐 성격의 자료구조), Cliff Click 의 논 블로킹 해시맵이 그것이다. 자바 컨커런시 레퍼런스 페이지에서 더 많은 자료를 찾아볼 수 있다.
논 블로킹 알고리즘의 이점
블로킹 알고리즘과 비교하여 논 블로킹 알고리즘의 몇가지 이점이 있다.
선택
논 블로킹 알고리즘의 첫 번째 이점은, 쓰레드가 요청된 작업을 수행할 수 없는 경우 어떤 동작을 취할 지 선택할 수 있다는 것이다. 그저 동작을 정지하고 대기하는 대신, 쓰레드는 무엇을 할지 선택할 수 있다. 물론 쓰레드가 할 일이 없는 경우도 있을 수 있다. 이런 경우에는 스스로 동작을 정지하고 대기하도록 할 수 있다. 이렇게 함으로 CPU 자원은 는 다른 작업을 위해 쓰일 수 있을 것이다. 어쨌든 적어도 쓰레드는 선택권을 갖는다.
단일 CPU 시스템에서 요청된 동작을 수행할 수 없는 쓰레드를 정지시키는 일은 합리적이다. 이렇게 하면 다른 쓰레드가 CPU 를 사용하여 작업을 수행할 수 있다. 하지만 단일 CPU 시스템에서도 블로킹 알고리즘은 데드락이나 기아상태, 기타 다른 동시성 문제를 야기할 수 있다.
노 데드락
논 블로킹 알고리즘의 두 번째 이점은, 한 쓰레드의 정지가 다른 쓰레드의 정지를 일으키지 않는다는 것이다. 이 말은 데드락이 발생하지 않음을 의미한다. 두 쓰레드가 서로의 락이 해제되기를 기다리는 상황은 발생하지 않는다. 요청된 동작을 수행할 수 없는 쓰레드라도 정지되어 대기 상태로 들어가지 않기 때문이다. 논 블로킹 알고리즘에서도 라이브 락은 발생할 수 있다. 두 쓰레드가 요청된 동작을 수행하려 하지만 다른 쓰레드의 동작 수행으로 인해 이 동작이 수행 불가능한 상황이다. 두 쓰레드는 수행 불가능을 통보받지만 계속해서 수행을 시도한다.
노 쓰레드 서스펜션
쓰레드를 정지하고 활성화하는 일에는 비용이 든다. 운영체제와 쓰레드 라이브러리가 발전해가면서 줄어들어들긴 했지만, 쓰레드 정지와 활성화를 위한 비용은 여전히 크다.
쓰레드는 동작이 차단되면서 정지 상태가 된다. 따라서 쓰레드 정지-활성화 오버헤드를 일으킨다. 논 블로킹 알고리즘에서 쓰레드는 정지되지 않기 때문에, 이 오버헤드는 발생하지 않는다. CPU 는 컨택스트 스위칭에 사용될 잠재적인 시간 비용을 실제 비즈니스 로직을 수행하는 데에 사용할 수 있다는 뜻이다.
멀티 CPU 시스템에서 블로킹 알고리즘은 전체적인 성능에 있어 큰 영향을 미칠 수 있다. CPU A 에서 동작하는 쓰레드가 CPU B 의 쓰레드를 기다리며 정지될 수 있다. 이는 어플리케이션의 병행성을 낮추게 된다. 물론 CPU A 는 다른 쓰레드가 동작하도록 조정할 수 있을 것이다. 하지만 쓰레드의 정지-활성화라는 컨텍스트 스위칭 비용은 비싸다. 쓰레드가 정지되지 않는 편이 낫다.
쓰레드 지연 감소
여기서 지연이란 요청된 동작이 수행 가능해진 시점부터 실제로 쓰레드가 동작을 수행하는 시점까지의 시간을 의미한다. 논 블로킹 알고리즘에서 쓰레드는정지되지 않기 때문에 쓰레드 활성화에 드는 비싸고 느린 비용을 지불하지 않는다. 이는 어떤 요청 동작이 수행 가능해지면 쓰레드는 보다 빠르게 응답을 줄 수 있다는 의미이다. 따라서 응답 지연은 감소한다.
논 블로킹 알고리즘은 요청 동작이 수행 가능해질 때까지 바쁜 대기(busy-waiting)를 통해 지연을 낮춘다. 물론 논 블로킹 자료구조에 대한 쓰레드 경합이 높아지면 CPU 는 바쁜 대기에 많은 싸이클을 소모하게 된다. 이 사실은 염두에 두어야 한다. 당신의 자료구조가 높은 쓰레드 경합을 가진다면 논 블로킹 알고리즘은 최선이 아닐 수 있다. 그러나 쓰레드 경합을 낮추도록 어플리케이션을 재설계하는 방법도 존재한다.